들어가며
'동시성 문제'는 CS 공부를 하거나, 백엔드 개발을 하다 보면 종종 마주하는 문제입니다. 저 역시도 프로젝트 개발 과정에서 본래 상승해야 하는 값이 아닌 다른 값으로 update 되는 케이스를 마주한 경험이 있었습니다. 문제를 해결하기 위해서 전에 공부했던 지식과 기술 블로그, GPT 등을 통해 공부하며 느낀 점은, 선택지가 굉장히 다양하다는 점이었습니다.
아무래도 우리는 개발자니까, 많은 선택지 가운데서 각각의 특징을 이해하고, 서비스와 팀의 상황에 가장 적합한 방법을 고려하는 것이 중요하죠. 이번 글에서는 제가 준비한 여러 방법들에 대한 간단한 개념과 특징, 그리고 적용 방법에 대한 예제를 소개하겠습니다. 그리고 마지막에는 충돌 상황에서 각 방법에 대한 성능 테스트를 진행한 결과를 표와 그래프를 통해 성능을 한눈에 볼 수 있도록 준비해 봤습니다. 각 방법에 대해서 알아보며 특징과 사용 방법을 익혀봅시다.
Spring에서 사용할 수 있는 다양한 동시성 제어 방법
이 글에서 제가 준비한 방법은 Java에서 사용 가능한 synchronized 키워드와 ReentrantLock 클래스, 데이터베이스의 Exclusive Lock(JPA의 PessimisticLock WriteMode), Optimistic Lock, Redis를 활용한 Lettuce 기반의 spin lock과 Redisson 기반의 pub-sub 방식의 lock입니다. 이에 대해서 자세히 알아보기 이전에 예제 프로젝트 구조에 대해서 잠시 설명하겠습니다.
예제 프로젝트 간단 소개
예제 프로젝트는 동시성 관련 문제를 학습하며 들어봤던 은행 송금 시스템입니다. A가 B에게 돈을 보내면, A의 계좌에선 돈이 빠져나가고, B의 계좌에선 돈이 추가되는 간단한 구조입니다.
ERD는 아래 그림과 같이 간단한 구조입니다. 별 다른 내용은 없지만 version 같은 경우는 이후 Optimistic Lock을 활용하기 위해 추가했습니다.
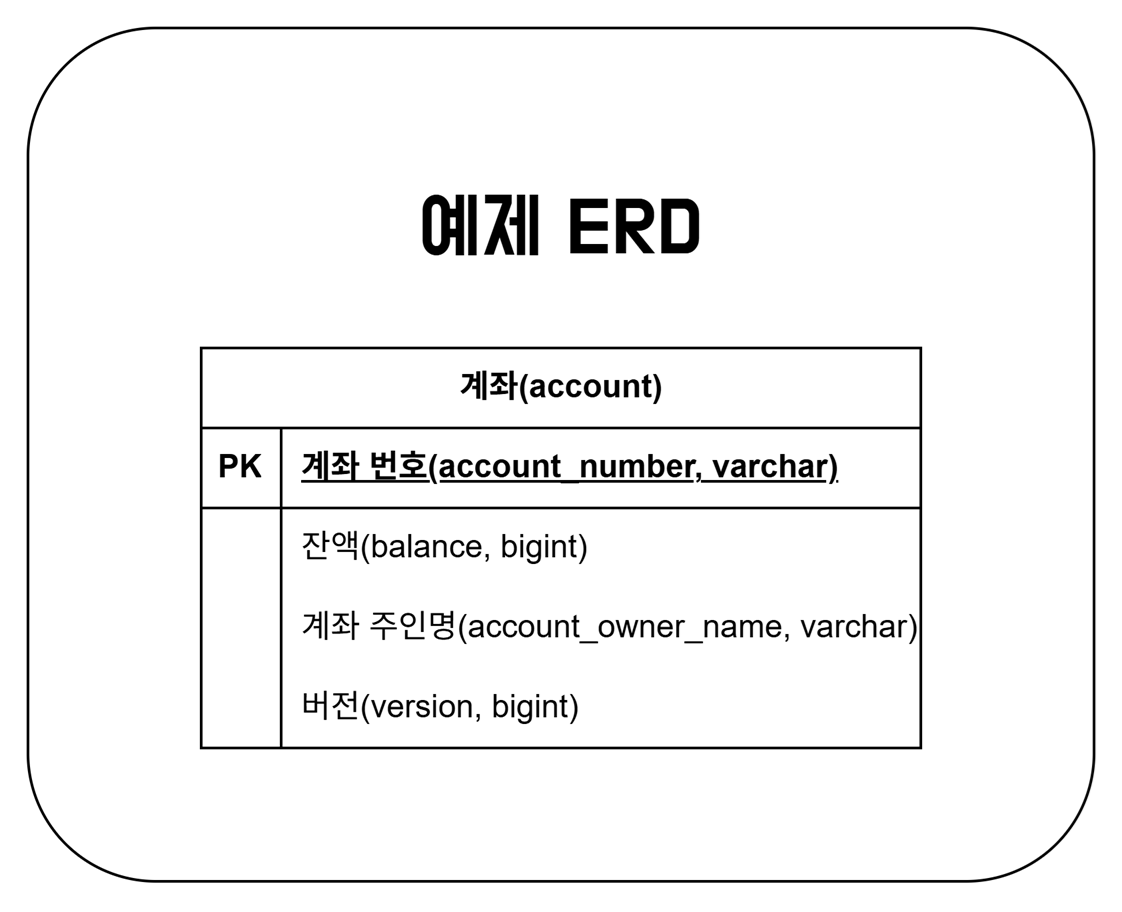
이 링크를 클릭하시면 예제 프로젝트 전체를 확인할 수 있습니다.
그럼 이제 본격적으로 동시성 제어 방법에 대해서 알아봅시다.
각각의 방법에 대해서는 특징 -> 사용방법 순으로 작성해 봤습니다. 방법에 대한 이해를 갖고 나서, 사용을 해봅시다.
synchronized
특징
처음으로 알아볼 방법은 Java의 synchronized 키워드입니다. synchronized는 메서드 시그니쳐에서 사용하거나, 메서드 본문 내에 블록 형태로 사용할 수 있습니다. Monitor라고 표현하는 클래스가 가진 내재적인 Lock을 획득하여 메서드에 대한 독점적이고 일관된 접근이 가능하게 합니다.
synchronized의 특징이라고 하면 크게 2가지를 고를 수 있습니다.
첫 번째는 Spring AOP와 함께 적용되는 상황에서 동시성 제어 범위를 제대로 체크해야 한다는 점입니다. 주로 동시성 제어가 필요한 상황에서는 `@Transactional` 어노테이션을 함께 사용합니다. 그렇게 될 경우 Spring AOP에 의해 프록시가 해당 메서드를 가로채서 동작하고, 프록시 내부 로직에서 트랜잭션을 관리해 줍니다. 하지만, 실제로 동작하는 클래스는 프록시 클래스이고, synchronized로 인해 관리되는 제어 범위는 본래 클래스이기 때문에, 아래 그림과 같은 형태가 됩니다.
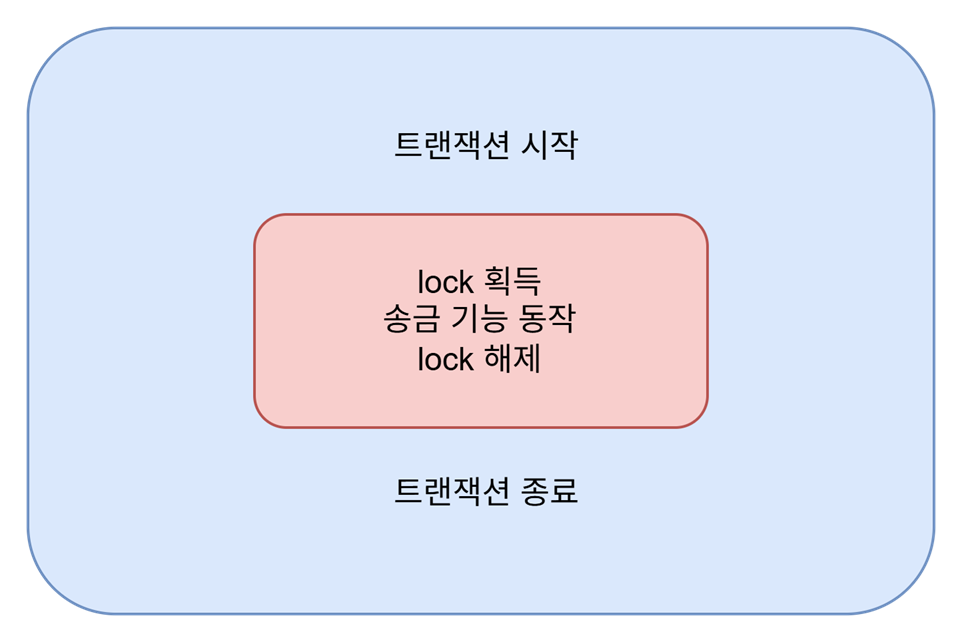
이처럼 커밋이 되는 순간에는 lock을 가지고 있지 않기 때문에 새로 lock을 획득한 쓰레드는 커밋 이전의 데이터를 조회할 수 있고, 그로 인해서 의도하지 않은 값으로 수정이 발생하게 됩니다. 이런 부분을 고려해 synchronized를 사용할 때엔 Facade 클래스를 생성하고, 해당 클래스에 제어를 걸어 주어야 원하는 방법으로 동작이 가능합니다.
두 번째 특징은, 복수의 서버가 존재하는 상황에서는 동작하지 않는다는 점입니다. Java에서 사용하는 동시성 제어 방법은 모두 하나의 프로세스에서만 적용됩니다. 그렇기 때문에 다른 프로세스에는 영향을 줄 수 없고, 제어가 불가능합니다.
사용 방법
앞서 설명했던 것처럼, Facade 클래스를 사용해야 동시성 제어가 가능합니다. 아래 코드와 같은 형태를 이루게 된다면 트랜잭션을 처리하는 프록시까지도 lock 범위 내부에 들어가기 때문에 예상 가능한 결과를 보장할 수 있습니다.
@RequiredArgsConstructor
@Component
public class SynchronizedFacade {
private final BaseAccountService baseAccountService;
public synchronized void send(SendRequest request) {
baseAccountService.send(request);
}
}
ReentrantLock
특징
ReentrantLock은 Java에서 제공하는 Lock 인터페이스의 구현체 중 하나로서, synchronized와 마찬가지로 암시적으로 monitor lock에 접근, 사용합니다. 하지만 synchronized에 비해서 더 다양한 기능을 제공한다는 점이 특징입니다.
Java에서 제공하는 기능이자, synchronized와 유사한 방식으로 동작하기 때문에 주의할 점 역시 유사합니다. 단일 인스턴스에서만 동작한다는 점, Spring AOP로 인해 트랜잭션 프록시를 고려해서 Facade 클래스를 생성해서 사용해 줘야 정상적으로 동작한다는 점을 인지하고 사용합시다.
사용 방법
순수하게 동시성 제어만을 위한 사용 방법은 굉장히 간단하고, synchronized와 크게 차이는 없습니다. 아래 코드와 같이 ReentrantLock을 생성하고, 동시성 제어 범위 내에서 lock을 걸어주고, 해제를 해줍니다. 본래 로직에서 예외가 발생할 수 있기 때문에, finally 구문으로 unlock을 해주는 것이 중요합니다.
@RequiredArgsConstructor
@Component
public class ReentrantLockFacade {
private final BaseAccountService baseAccountService;
private final ReentrantLock lock = new ReentrantLock();
public void send(SendRequest request) {
lock.lock();
try{
baseAccountService.send(request);
}finally {
lock.unlock();
}
}
}
Database Exclusive Lock
특징
데이터베이스의 쓰기 락(배타 락)의 경우 특정 범위의 데이터에 물리적인 lock을 걸어서 다른 트랜잭션이 해당 데이터에 접근하는 것을 막습니다. 정확하게는 해당 데이터에 추가적인 락(공유 락, 배타 락)을 걸지 못하게 합니다. lock이 걸리게 된다면, 해제될 때까지 다른 트랜잭션을 대기하고, 접근할 수 있어, 동시성 제어가 가능합니다.
Exclusive Lock의 경우 Row나 테이블에 대해서 lock을 적용합니다. synchronized나 ReentrantLock이 동일한 메서드에 대해서 접근을 제어했다면, 이 방법은 데이터를 기준으로 접근을 제어합니다. 그렇기에 서로 다른 기능에게도 성능적인 영향을 줄 수 있습니다.
개인적으로 헷갈렸던 부분으로는 Exclusive Lock을 사용하게 되면 일반적인 조회도 불가능하다고 생각했습니다. 하지만 lock을 사용하지 않는 조회의 경우 정상적으로 사용할 수 있기 때문에, 해당 기능에 성능 저하는 발생하지 않았습니다.
그 외에는 데이터베이스에서 동시성 제어를 하기 때문에, 복수의 서버 환경에서도 안전하게 동작할 수 있다는 점과 별도의 Facade 클래스를 만들지 않아도 됩니다.
사용 방법
사용 방법에 대해서는 2가지 방법을 소개하겠습니다.
첫 번째는 JPA를 사용하는 경우입니다. 간단하게 조회 메서드에 `@Lock`이라는 어노테이션을 추가해서 사용할 수 있습니다. 그리고 `LockModeType.PESSIMISTIC_WRITE`을 속성 값으로 넣어주면 됩니다. JPA에서의 @Lock 어노테이션에는 다양한 옵션이 존재하고, 그중에서 PESSIMISTIC_WRITE 이것이 데이터베이스의 배타 락을 사용하는 키워드입니다. 이를 비관 락이라고도 부르며, 충돌이 자주 발생할 것을 가정하고 사용하는 락을 의미합니다. 아래 코드와 같이 사용할 수 있습니다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select a from Account a where a.accountNumber = :accountNumber")
Optional<Account> findByIdWithPessimisticWrite(String accountNumber);
두 번째는 Native Query로 작성하는 것입니다. 사실 데이터베이스의 Exclusive Lock은 `select ~~~ for update` 구문으로 동작합니다. 아래 코드처럼 해당 쿼리를 직접 작성해 주시면 쉽게 이용이 가능합니다.
@Query(value = "select * from account where account_number = :accountNumber for update", nativeQuery = true)
Optional<Account> findByIdWithNativeQueryLock(String accountNumber);
Optimistic Lock
특징
충돌이 자주 발생하지 않을 것을 전제로 사용하는 동시성 제어 기법으로, 물리적 Lock을 사용하지 않고 커밋 시점에서 데이터의 버전 비교를 통해 충돌을 감지합니다. 한번 업데이트가 될 때마다 버전 값을 +1씩 올려주고, 버전이 다르다면 전체 로직을 재시도하는 형태로 동작합니다.
재시도 로직으로 인해 실제 충돌이 발생하게 될 경우 타 방법에 비해서 큰 성능 저하가 발생하게 됩니다. 하나의 트랜잭션을 너무 길게 사용하지 않는 것을 통해 이를 줄일 수 있습니다.
사용 방법
JPA를 활용하면 많은 동작에 대해서 간단하게 처리해 주기 때문에, 이번 예제에서는 JPA를 사용하는 것을 전제로 진행하겠습니다. 우선은 아래와 같이 JPA 엔티티에 version이라는 필드를 추가하고 `@Version` 어노테이션을 추가해 줍니다.
@Version
private long version;
그리고 앞선 Exclusive Lock처럼 새로운 조회 메서드를 만들고, `@Lock(LockMode.OPTIMISTIC)` 을 설정해 줍니다. 제가 테스트해봤을 때는, @Version이 사실 중요한 부분이라서 이 메서드는 크게 중요하지는 않다고 하지만, 명시적으로 Lock이 동작한다는 것을 알리는 의미가 있다고 생각합니다.
@Lock(LockModeType.OPTIMISTIC)
@Query("select a from Account a where a.accountNumber = :accountNumber")
Optional<Account> findByIdWithOptimisticLock(String accountNumber);
마지막으로는 재시도 로직을 작성해 줍니다. 아래와 같이 작성을 해봤습니다. 반복문에서 반복하는 횟수나 쓰레드가 대기하는 기간은 적절하게 설정해 주시면 됩니다.
while (true) {
try{
optimisticLockAccountService.sendWithDataJpaOptimisticLock(request);
break;
}catch (ObjectOptimisticLockingFailureException e){
try {
Thread.sleep(100);
} catch (InterruptedException ex) {
throw new RuntimeException(ex);
}
}
}
Spring Data JPA에서 제공하는 기능 외에도 기본 jpa인 EntityManager를 활용하는 방법도 존재합니다. 실제로는 사용하지 않겠지만, 아래와 같은 방법으로 조회하면 똑같은 기능으로 동작합니다.
entityManager.createQuery("select a from Account a where a.accountNumber = :accountNumber", Account.class)
.setParameter("accountNumber", request.senderAccountNumber())
.setLockMode(LockModeType.OPTIMISTIC)
.getSingleResult();
다만 이 두 방법의 차이는 Spring Data JPA의 기능을 활용할 때엔 `ObjectOptimisticLockingFailureException` 이 예외가 발생하고, EntityManager를 사용할 때엔 `OptimisticLockException` 이 예외가 발생하기 때문에 알맞게 적용해 주면 될 것입니다.
Redis Lettuce Lock
특징징
Spring에서 기본적으로 사용하는 레디스 라이브러리인 Lettuce를 기반으로 만드는 동시성 제어 방법입니다. Redis의 setnx( SET if Not eXists) 명령어를 통해 Lock을 사용하는 방법입니다. Redis는 싱글 스레드 기반으로 모든 명령어를 순차적으로 처리하기 때문에 SETNX 명령 자체는 원자적으로 동작하기 때문에, 이를 통해 기본적인 락 구현이 가능합니다.
Redis를 활용한 Lock을 분산 락이라고도 부릅니다. 앞서 있었던 데이터베이스를 활용한 방법은 하나의 DB에서만 가능한 방법입니다. 하지만 여러 데이터베이스를 사용하고, 혹은 DB의 제품마저 다른 상황이라면 제어가 불가능하기 때문에 Redis와 같은 독립적인 시스템을 활용해서 분산 환경에서의 제어가 가능하기 때문입니다.
분산 락을 구현할 수 있다는 점 이외의 특징으로는, Redis를 추가로 사용해야 하기 때문에 비용이 발생할 수 있다는 점, Spin-Lock 형태이기 때문에 대기에 있어서 공정성을 보장할 수 없어 타임아웃이 될 수도 있다는 점을 고려하면 될 것 같습니다.
사용 방법
Redis의 RestTemplate의 `setIfAbsent`는 앞서 본 setnx 명령어를 사용하는 메서드입니다. 이를 활용해 lock을 생성해 주는 메서드를 제작합니다.
public Boolean getLock(String name){
ValueOperations<String, String> ops = redisTemplate.opsForValue();
return ops.setIfAbsent(generateKey(name),name,1000, TimeUnit.MILLISECONDS);
}
이후 락을 사용한 이후에 해제하는 명령어까지 제거하면 기본적인 구성이 완료됩니다.
public Boolean releaseLock(String name) {
return redisTemplate.delete(generateKey(name));
}
Lettuce를 활용한 방법은 Optimistic Lock과 유사한 형태로 작성됩니다. Lock을 획득하지 못하면 Lock 획득을 재시도하는 Spin Lock 형태로 동작하며, 본래 동작 이후에는 finally 구문을 통해 결과와 관계없이 lock을 해제해 줍니다.
Redis Redisson Lock
개념
Redis에서 제공하는 Redisson 라이브러리를 기반으로 구현한 Lock 방법입니다. 앞선 Lettuce가 setnx 명령어로 구현한 방법과는 다르게 pub-sub 기반으로 동작하며, 자신의 차례가 왔을 때 Lock을 획득하고 본래 동작을 이어갑니다.
이 방법의 특징은 추가로 Redisson 라이브러리에 대한 의존성을 추가해야 하고, 사용 방법을 익혀야 한다는 점입니다. 그 외에는 Lock에 대한 기능이 자체적으로 구현되어 있어 사용에서 편리하고, pub-sub 기반 동작과 결합되어 충돌 상황에서 높은 성능을 보입니다. 실제로 Redis를 활용해 Lock을 구현할 경우, 가장 권장되는 방법입니다.
사용 방법
라이브러리 차원에서 Lock 사용을 구현해 뒀기 때문에 사용 방법은 간단합니다. `getLock`이라는 메서드로 Lock을 활용할 수 있는 클래스를 생성하고, `tryLock` 메서드를 활용해 Lock을 획득합니다. 어느 시간 동안 락 획득을 위해 대기를 할 것인지를 파라미터로 넣게 되고, 해당 시간 동안 획득하지 못하면 false가 나와 종료됩니다. 원하는 상황에 맞춰서 설정하면 될 것 같습니다. 다른 방법들과 마찬가지로 finally에서 unlock을 시켜줍니다. 해당 과정에서 lock을 갖지 못한 쓰레드가 unlock을 하는 경우(!available에서 return 된 경우) 에는 IllegalMonitorStateException이 발생할 수 있어 이를 처리해 줍니다. 그 외에는 별다른 작업 없이 동작이 가능합니다.
public void sendWithRedissonLock(SendRequest request) {
RLock rLock = redisson.getLock("send");
try {
boolean available = rLock.tryLock(5L, 3L, TimeUnit.SECONDS); // (2)
if (!available) {
return;
}
accountService.send(request);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
try {
rLock.unlock(); // (4)
} catch (IllegalMonitorStateException e) {
}
}
}
마무리
지금까지 제가 준비한 동시성 제어 방법에 대한 전반적인 특징과 사용법에 대해서 알아보았습니다. 각 방법에 대한 이해를 높이는데 도움이 되셨으면 좋겠습니다.
아래 차트는 앞서서 보았던 예제 기능에 대해서 지속적인 충돌이 발생한 경우에 대한 성능 테스트를 진행한 결과입니다.
충돌 상황에 대한 테스트 환경은 아래 표로 정리하겠습니다.
| 테스트 유저 | 100 |
| 기간 | 5분 |
| 부하 도구 | JMeter (Local PC) |
| DB | MariaDB 10.6 (AWS RDS) |
| Redis | version 8.0.2(AWS EC2) |
| Spring Boot | version 3.5.0 (Local PC) |
| Local PC CPU | AMD Ryzen7 8845HS |
| Local PC RAM | 32GB |

이 표를 본다면 지속적인 충돌이 발생하게 되는 상황에서는 아무래도 충돌을 염두하고 만든 Exclusive Lock의 성능이 뛰어나다는 것을 확인할 수 있습니다. 하지만 오직 1개의 기능으로만 테스트했기 때문에, 여러 기능들이 동시에 동작하면 성능이 떨어질 수도 있겠네요. 그 외에는 Redisson의 TPS가 굉장히 높았습니다. 그래서 여러모로 선택되는 방법인 것을 알 수 있었고, 충돌이 잦은 환경에서는 Optimistic Lock의 성능이 확실히 떨어지는 것을 볼 수 있었네요.
각각의 특징을 고려해서 방법을 선택하면 좋을 것 같습니다. 충돌이 자주 발생한다면 Exclusive Lock을, 분산 환경에서 여러 DB를 활용한다면 Redisson을 활용하면 좋겠습니다. 물론 대다수의 서비스들은, 동시에 100명이 5분 동안 충돌을 발생하지는 않을 테니 Optimistic Lock 사용이 이롭다고 생각이 됩니다. 이 블로그를 제가 직접 운영한다고 했을 때, 하루에 20명 정도가 보는데 아무래도 충돌을 걱정할 필요가 없겠죠? 모든 기술들의 특징과 자신이 운영하는 서비스의 상황을 잘 고려해서 적용할 수 있도록 합시다.
참고 자료
컬리 기술 블로그 - 풀필먼트 입고 서비스팀에서 분산락을 사용하는 방법 - Spring Redisson
오라클 Java 튜토리얼 - Intrinsic Locks and Synchronization
인프런 최상용 - 재고시스템으로 알아보는 동시성이슈 해결방법