인덱스란?
이 글을 보는 대다수의 사람들은 이미 인덱스에 대한 기본적인 지식이 있으실겁니다. 자세히 아시는 분은 가벼운 마음으로 제가 작성한 내용을 봐주시고, 아직 정리가 안된 분은 함께 인덱스를 정리해나가며 읽어주시면 좋겠습니다.
인덱스의 정의
우리가 흔히 데이터베이스에서 사용하는 인덱스의 본래 뜻은 무엇일까요? 인덱스를 사전에 검색하면 `색인`이라는 말이 나옵니다. `색인`이라는 단어를 일상에서 많이 사용하지는 지는 모르겠지만, 우리가 책을 볼 때 가장 마지막 부분에서 볼 수 있는 단어 혹은 용어가 어떤 페이지에서 등장했는지를 알려주는 페이지입니다.

그 페이지처럼 데이터베이스에서 우리가 원하는 정보(Row)를 빠르게 찾을 수 있게 해주는 것이 바로 인덱스(Index)의 기능이자 목적입니다.
인덱스는 왜 빠를까?
그럼 왜 인덱스를 이용하면 정보를 빠르게 찾을 수 있을까요? 상상해 보시면 우리가 데이터베이스와 관련된 책을 구매하고, 거기서 `인덱스`라는 단어가 어디 있는지 찾고자 한다면 목차나 색인 페이지가 없다면, 전체 페이지를 뒤져보면서 단어를 찾아야 할 것입니다. 굉장히 많은 시간이 들죠.
하지만 색인 페이지가 있다면 우리는 굉장히 빠르게 정보를 찾을 수 있습니다.

이는 인덱스가 특정 단어에 대해서 어디에 위치해 있는지를 알려줄 뿐만 아니라, 정렬된 구조를 가져 단어를 찾기 쉽게 해 주기 때문이죠. 위 사진처럼 A-Z로 정렬된 페이지를 가지고 있고 위 사진에서 A-F까지의 정보만 다루고 있기 때문에 우리는 다음 페이지에서 I가 있는지를 찾고 그중에서 Index를 찾아가면 될 것입니다.
이런 이유는 데이터베이스 역시 동일합니다. MySQL의 공식 문서에서는 다음과 같이 이야기합니다.
Indexes are used to find rows with specific column values quickly.
Without an index, MySQL must begin with the first row and then read through the entire table to find the relevant rows.
The larger the table, the more this costs. If the table has an index for the columns in question, MySQL can quickly determine the position to seek to in the middle of the data file without having to look at all the data. This is much faster than reading every row sequentially. - 10.3.1 How MySQL Uses Indexes
굵게 표시한 부분만 해석하면, 인덱스가 없으면 원하는 row를 찾기 위해 모든 테이블을 뒤져야 하지만, 인덱스가 있다면 빠르게 어떤 위치에서 찾아야 할지 결정할 수 있고, 이런 경우 모든 데이터를 볼 필요가 없다는 것을 말합니다. 우리가 색인 페이지에서 단어를 찾는 것처럼 MySQL의 엔진 역시 인덱스를 통해 빠르게 데이터를 가져올 수 있습니다.
인덱스의 구조
인덱스는 정렬된 형태를 띠고 있기 때문에, 빠른 검색이 가능하다고 했습니다. 대체 어떤 자료구조를 이용하길래 정렬된 구조에서 좋은 검색 성능을 이뤄낼 수 있을까요? 이는 많은 사람들이 이미 알고 있겠지만 `B-Tree`의 구조를 채용하고 있습니다.
MySQL의 공식문서에서는 다음과 같이 설명합니다.
InnoDB indexes are B-tree data structures. (…) Index records are stored in the leaf pages of their B-tree.
- 17.6.2.2 The Physical Structure of an InnoDB Index
B-tree
A tree data structure that is popular for use in database indexes. The structure is kept sorted at all times, enabling fast lookup for exact matches (equals operator) and ranges (for example, greater than, less than, and BETWEEN operators). (…) The use of the term B-tree is intended as a reference to the general class of index design. B-tree structures used by MySQL storage engines may be regarded as variants due to sophistications not present in a classic B-tree design.
- MySQL Glossary B-Tree
B-Tree를 이용해서 정렬된 구조를 이루고, 리프 노드에 인덱스 레코드를 저장하는 것으로 검색의 효율을 높이고 있는데요, 리프 노드에만 정보를 저장한다는 점은 기본적인 B-Tree의 형태보다는 B+Tree의 형태에 조금 더 유사한 듯싶고, 아래 문단에서 언급한 것처럼 MySQL만의 B-Tree 자료 구조를 가지고 있는 듯싶습니다.
인덱스의 구조를 이해하기 쉽게 그림으로 보면 아래와 같이 표현할 수 있습니다. 인덱스로는 수업 번호(class_id)와 학생 번호(student_id)를 이용했으며, 마지막 Leaf노드에서는 실제 데이터의 주소인 Pointer를 가지고 있어, 이를 통해 실 데이터의 정보를 얻을 수 있습니다. 이때 포인터에 들어갈 값은 클러스터형 인덱스만 있는 경우 or 세컨더리 인덱스만 있는 경우, 둘 다 있는 경우에 따라서 값이 다르지만 어떤 값이 오더라도 실 데이터에 더욱 빠르게 접근을 하는데 도움을 줍니다.
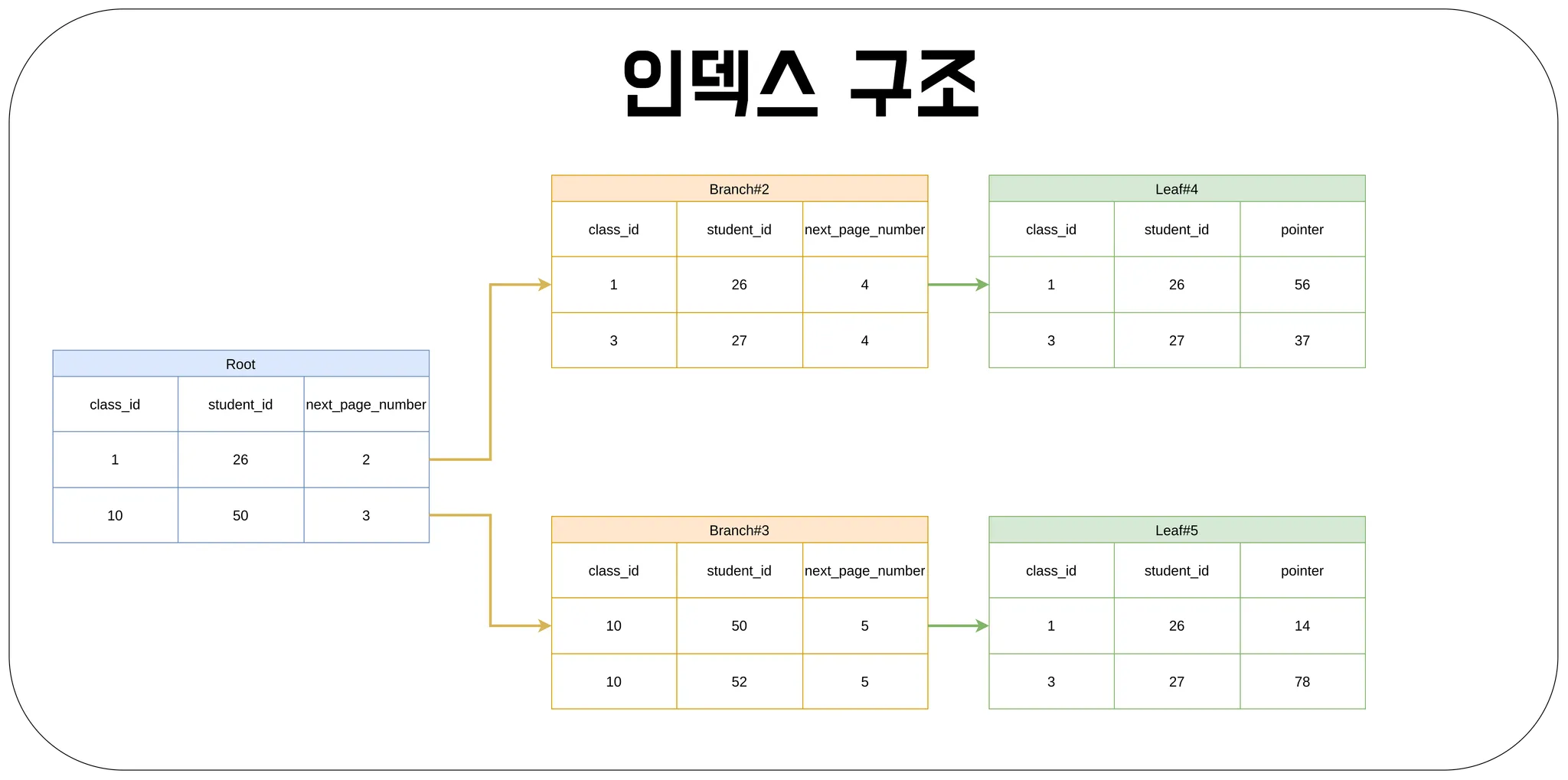
인덱스의 종류
앞선 내용에서 클러스터형 인덱스, 세컨더리 인덱스라는 용어를 사용했습니다. 이 둘은 MySQL에서의 인덱스에 대한 두 종류를 나타냅니다. 이들은 모두 위에서 본 인덱스 구조의 그림의 형태로 저장이 되지만, 생성되는 방법, 저장되는 위치에서 차이를 보이고 있으며, 특징에서도 미묘한 차이를 보입니다. 이 두 종류의 인덱스에 대해서 공식문서에서 설명하는 것을 알아봅시다.
1. 클러스터형 인덱스
클러스터형 인덱스는 테이블이 특별하게 가지는 인덱스로, 일반적으로 PK 동의어로 사용됩니다. 클러스터형 인덱스는 데이터베이스에서 데이터를 저장하는 페이지에 직접적으로 영향을 주기 때문에, 다른 인덱스에 비해서 데이터에 대한 접근 속도가 훨씬 빠릅니다. 이런 특징으로 인해서 MySQL의 InnoDB는 클러스터형 인덱스를 이용해 각종 DML에 대해서 최적화를 진행합니다.
앞서서 클러스터형 인덱스는 PK와 동일하다고 이야기를 했습니다. 유저가 PK를 지정을 할 때엔, 일반적으로 유니크하고 null이 아닌 Column의 집합에 대해서 PK를 설정하거나, 혹은 auto_increment가 되는 임의의 값에 설정을 하게 됩니다. 그리고 클러스터형 인덱스는 PK가 설정된 colmn에 설정이 되고, 이를 기반으로 테이블의 데이터를 정렬합니다.
하지만 PK가 없는 경우에도 우리는 클러스터형 인덱스가 적용되어 어떠한 기준에 의해서 데이터가 정렬이 된 것을 확인할 수 있었습니다.
이런 경우엔 앞서서 이야기 한 Unique 한 값을 찾아서 클러스터형 인덱스로 자동으로 생성하게 됩니다. 그리고 이 역시 없는 경우, 사용자는 확인할 수 없는 `GEN_CLUST_INDEX`라는 인덱스를 만들고, 이를 기준으로 클러스터형 인덱스를 타게 됩니다. 그렇지만 `GEN_CLUST_INDEX`의 경우 힌트를 사용해서도 강제적으로 이용할 수 없고, `explain`을 통해서도 확인할 수 없다는 특징이 있습니다.
아래 사전처럼 테이블의 내용들이 별도의 공간을 사용하지 않고 정렬된 형태로 저장되어 있는 것이 클러스터형 인덱스의 특징입니다.

2. 세컨더리 인덱스
세컨더리 인덱스의 경우 사용자가 직접 생성한 인덱스 혹은 유니크 칼럼에 대해서 자동으로 생성되는 인덱스입니다. 공식 문서에 따르면, 세컨더리 인덱스의 리프 노드에서는 주로 본래 레코드의 PK를 지니고 있어 본래 데이터를 찾아갈 수 있도록 한다고 합니다. 하지만 위의 클러스터형 인덱스에서 봤던 PK가 없는 경우들이 있었기 때문에, 이 상황에서는 클러스터형 인덱스에 대한 포인터를 가지고 있어서 본래 데이터에 접근이 가능하다고 이해를 하면 될 것 같습니다.
세컨더리 인덱스의 경우 클러스터형 인덱스가 데이터가 직접 저장되는 테이블에 영향을 주는 것과 달리, 별도의 공간에서 정렬 상태를 이루는 구조를 가지고 있습니다. 이러한 특징으로 인해서 추가적인 저장공간을 사용한다는 점이 차이점이라고 할 수 있겠습니다.
이 두 내용에 대해서는 공식 문서의 영어가 좀 길어서 직접 인용하지는 않고, 정리를 했는데요. 본문을 보고 싶으시다면 이 링크를 클릭해서 더 자세한 내용을 보실 수 있습니다.
인덱스 사용 방법
지금까지 인덱스에 대한 정의 및 기본적인 개념에 대해서 알아봤으니, 실제로 사용하는 방법에 대해서 알아보려고 합니다. 이 파트에서는 인덱스를 생성하는 방법, 적용이 되었는지 체크하는 방법, 적용이 되도록 유도(Hint 사용)하는 방법과 인덱스 목록 조회, 삭제 방법을 알아보고 마무리하려 합니다.
인덱스 생성하기
인덱스를 생성하는 방법은 크게 2가지 방법으로 `create table` 문을 실행할 때, 함께 작성하는 방법과 `create index`문을 사용해 따로 추가하는 방법이 있습니다.
1. create table
create table 문에서는 일반적인 column을 정의한 이후 PK나 FK를 지정하는 것과 같이 `index`를 지정할 수 있습니다. 아래 예시를 통해서 같이 보겠습니다.
create table parent
(
id int not null auto_increment,
name varchar(10) not null,
age int not null,
primary key (id)
);
create table child
(
id int not null auto_increment,
name varchar(10) not null,
age int not null,
student_id int not null,
parent_id int not null,
index idx_name (name),
unique (student_id),
primary key (id),
foreign key fk_parent_id (parent_id) references parent (id)
);
child 테이블을 보면 `index idx_name (name)`을 입력하는 것으로 인덱스를 지정해 주는 것을 볼 수 있습니다. 또한 직접적인 index생성문을 작성하지 않더라도 PK, FK, Unique 옵션이 걸린 부분은 자동으로 인덱스가 생성됩니다. 이 테이블에서는 unique와 PK, FK를 모두 설정을 해주어 총 4개의 인덱스가 생성될 것으로 예상이 되는데요. 실제로도 4개의 인덱스가 생성된 것을 확인할 수 있습니다.

테이블을 설계할 때 이미 어떤 열들이, 조건문이나 join절에서 자주 사용될 거라고 생각이 들면 테이블을 정의할 때 같이 인덱스를 생성하면 일을 두 번 하지 않아 좋겠다고 생각이 듭니다.
2. create index
다음 방법은 create index 문을 이용하는 것입니다. create index를 적용하는 방법은 크게 어렵지는 않습니다. `create index {index_name} on {table_name}({column_name})` 을 적용하면 됩니다. 앞서서 봤던 parent 테이블에도 이름에 인덱스를 걸어보면 아래와 같이 될 것입니다. `create index idx_parent_name on parent(name);`
create index문의 경우는 앞서서 create table과 다르게 테이블을 생성한 이후에도 인덱스를 설정할 수 있다는 장점이 있습니다. 서비스를 운영하는 도중 특정한 컬럼에 대한 조건 검색 기능에 대한 요청이 자주 발생하는 경우 혹은 해당 기능에 대한 성능 이슈가 발생할 때 인덱스 적용을 고려할 때 사용하기 좋아 보입니다.
인덱스가 적용됐는지 확인하기
인덱스를 생성했다면, 이제는 인덱스가 제대로 적용되는지를 확인해 보겠습니다. 인덱스가 적용되고 있는지를 체크하는 방법은 간단하게 쿼리의 실행계획을 확인하는 `explain` 키워드를 적용해 확인하면 됩니다.
`explain`키워드를 적용하면 쿼리의 실행에 대한 다양한 정보를 제공해 주지만 어떤 인덱스가 적용될지에 대한 정보로는 `possible_keys`와 `key`에 대한 정보를 확인하면 좋습니다.
- possible_keys : 사용할 수 있는 인덱스 종류를 보여준다.
- key : 실제로 적용된 인덱스를 보여준다.
앞서서 봤던 parent 테이블에 새로운 인덱스와 데이터를 넣은 후 우리가 생성한 인덱스가 아래의 select 문에서 제대로 탔는지 계획을 보면..
create index idx_parent_name_age on parent(name,age);
insert into parent(name, age) values ('kang',17), ('hong', 41);
explain
select * from parent where name = 'kim';
아래와 같이 두 개의 인덱스가 적용될 수 있고, 그 결과로 이름&나이로 생성한 인덱스가 적용이 된 것을 볼 수 있었습니다.

인덱스 힌트 사용하기
인덱스가 적용이 됐는데, 개인적으로 뭔가 이상합니다. 두 인덱스가 모두 `name`을 기준으로 정렬이 되어서 같은 결과를 도출한다고 해도, `name`만 사용한 인덱스가 더 효율적이라는 생각이 들기 때문입니다.
이 결과의 이유는 DB내부에서 동작의 최적화를 담당하는 옵티마이저가 해당 방법이 가장 최적화된 방법이라고 판단했기 때문입니다. 하지만 옵티마이저의 선택이 항상 옳은 경우만 존재하지는 않는다고 합니다. 이런 상황에서 우리는 옵티마이저가 우리가 원하는 선택을 하도록 알려주는 `Hint`를 사용합니다. `Hint`는 종류가 굉장히 많은데, 우리가 사용할 것은 Index를 선택하는데 도움을 주는 `Index Hint`입니다.
Index Hint는 크게 3가지 종류가 있습니다.
특정 Index를 사용하지 않게 하는 `Ignore Index`, 지정된 인덱스 중 하나를 선택하게 하는 `Use Index`, 마지막으로 Use Index와 유사하지만, 전체 테이블 스캔(인덱스를 타지 않는 것)을 매우 비싼 비용으로 평가하게 해 인덱스를 탈 확률을 더 높여주는 `Force Index`가 있습니다.
`Force Index`에 대해서 의문이 드실 수 있는데, `Use Index`를 사용하더라도, Full Table Scan이 더 효율적이라고 판단하면 인덱스를 이용하지 않는 경우도 있기 때문입니다.
사용하는 방법은 table 이름 뒤에 `{use} index이름` 그다음에 `{force|ignore} index이름`을 입력해 주면 됩니다.
위의 예시에서 `idx_parent_name` 이 더 효율적이라 판단하여 이를 사용하고자 한다면, `select * from parent use index(idx_parent_name) where name = 'kim';` 이렇게 입력하는 것으로 인덱스를 태우도록 할 수 있습니다.
그 결과 본래 사용되지 않았던 `idx_parent_name` 인덱스가 사용된 것을 볼 수 있습니다.

인덱스 목록 확인하기
지금까지 인덱스를 만들고, 사용하는 방법에 대해서 알아봤습니다. 이런 과정에서 인덱스를 이용할 때엔 인덱스의 이름을 이용한다는 것을 알 수 있습니다. 하지만 테이블의 컬럼도 아니고, 계속해서 인덱스의 이름을 확인할 일이 별로 없으니 인덱스 이름을 쉽게 기억하기는 어렵겠죠.
인덱스의 목록을 조회하는 방법은 굉장히 간단합니다. `show index from {table_name}` 을 통해서 간단하게 인덱스의 목록을 살펴볼 수 있습니다. 앞에서 `create table` 파트에서 4개의 인덱스의 존재를 확인한 명령어가 바로 이 명령어입니다.
이 외의 방법을 하나 더 알려드리자면 `select * from information_schema.INNODB_INDEXES;` 이 명령어를 이용해 추가적인 인덱스 정보를 획득할 수 있습니다. 아래 사진을 보면 앞서서 말했던 숨겨진 인덱스인 `GEN_CLUST_INDEX`의 존재도 체크할 수 있죠. 또한 공식적으로 나타나지는 않지만 여러 테스트를 통해 `TYPE` 필드의 값이 1인 경우 `GEN_CLUST_INDEX` , 2인 경우 `SECONDARY_INDEX` , 3인 경우는 `CLUSTERED_INDEX`라는 것을 어렴풋이 알 수 있었습니다. (사실이 아닐 수도 있습니다.)

이런 두 방법을 이용해 인덱스의 정보 조사하게 된다면, 조금 더 깊게 인덱스를 사용하는데 도움이 될 것 같네요.
인덱스 삭제하기
마지막으로 인덱스를 지우는 방법에 대해서 알아보겠습니다. 인덱스는 아무래도 추가적인 저장공간 사용 및 `B-Tree` 구조로 인한 삽입, 삭제, 수정 연산에서 정렬을 유지하기 위한 추가적인 작업이 소요된다는 특징이 있습니다. 이런 경우 자주 사용하지 않는 인덱스이거나, 조회보다 삽입, 수정, 삭제 연산이 더 빈번하게 발생한다면 인덱스를 유지하지 않는 편이 더 이롭겠죠.
이런 상황에서 인덱스를 삭제하는 명령어는 굉장히 간단합니다. `drop index {index_name} on {table_name}` 을 통해 삭제할 수 있습니다.
마무리
지금까지 인덱스에 대한 기본적인 개념 및 사용법에 대해서 알아보았습니다. 특히 첫 번째 단락에서 살펴본 인덱스 개념 및 정의 부분만 숙지하신다면 어디서 인덱스를 물어볼 때 쉽게 대답이 가능할 것 같습니다. 인덱스를 이용해서 조회 성능을 개선할 수 있다는 것을 알 수 있었는데, ‘그럼 모든 칼럼에 대해서 인덱스를 적용하는 것이 좋지 않으냐?’라는 의문이 생기실 수도 있겠습니다.
마지막 인덱스 삭제하기 파트에서 보면 인덱스를 이용하는 것은 추가적인 비용이 소모된다는 것을 말씀드렸죠. 그렇기 때문에 많은 부분을 고려해서 적용하는 것이 중요할 것 같습니다. 여기서 다루지 못한 인덱스에 관한 추가적인 정보는 이후 다른 글을 통해서 작성해 보겠습니다.
참고 자료
쉬운 코드 - DB 인덱스(DB index) !! 핵심만 모아서 설명합니다 !! (31분이 아깝지 않을 겁니다)
MySQL 8.4 - 10.3.1 How MySQL Uses Indexes
MySQL 8.4 - 15.1.15 CREATE INDEX Statement
MySQL 8.4 - 17.6.2.1 Clustered and Secondary Indexes
MySQL 8.4 - 17.6.2.2 The Physical Structure of an InnoDB Index