웹 백엔드 프로젝트를 진행하면, 많은 분들이 `Java`언어와 `Spring Boot` + `JPA` 혹은 `MyBatis` 조합을 사용해서 개발을 진행합니다. 저 역시 지금껏 Spring Boot를 활용해서 개발을 했었고, `JPA`와 `MyBatis` 모두 사용해 보았지만, 최근엔 `JPA`를 주로 사용하며 개발을 했습니다. `JPA`를 선택하면, 많은 편의성이 있지만, 가장 와닿는 점은 쿼리를 직접 작성하지 않아도 된다는 점이라고 생각합니다. 하지만 `JPA`가 직접 작성해 주는 쿼리는 저희의 생각과는 다르게 동작하는 경우도 존재합니다.
이 글은 `JPA`의 Delete 쿼리를 사용하면서 발견한 의아한 부분을 발견하고, 더 효율적인 방법을 찾아보려고 했던 내용에 대해서 다룹니다.
배경
최근 한 프로젝트를 진행하면서 Spring Boot와 JPA를 사용해 웹 백엔드를 구축해봤습니다. 이 프로젝트는 SNS와 관련된 프로젝트였습니다. 대표적인 SNS인 인스타그램과 같이 피드 기능이 있었고, 저는 피드를 삭제하는 API를 개발하는 도중 뭔가 이상함을 느꼈습니다.
프로젝트에서 사용된 피드와 관련된 구조는 아래 그림과 같습니다. 피드는 굉장히 많은 Entity들과 연관관계를 갖고 있기 때문에, 삭제의 편의성을 위해 JPA의 Cascade.Remove 옵션을 이용해 Feed를 Delete 할 때 쉽게 처리하려고 했습니다.
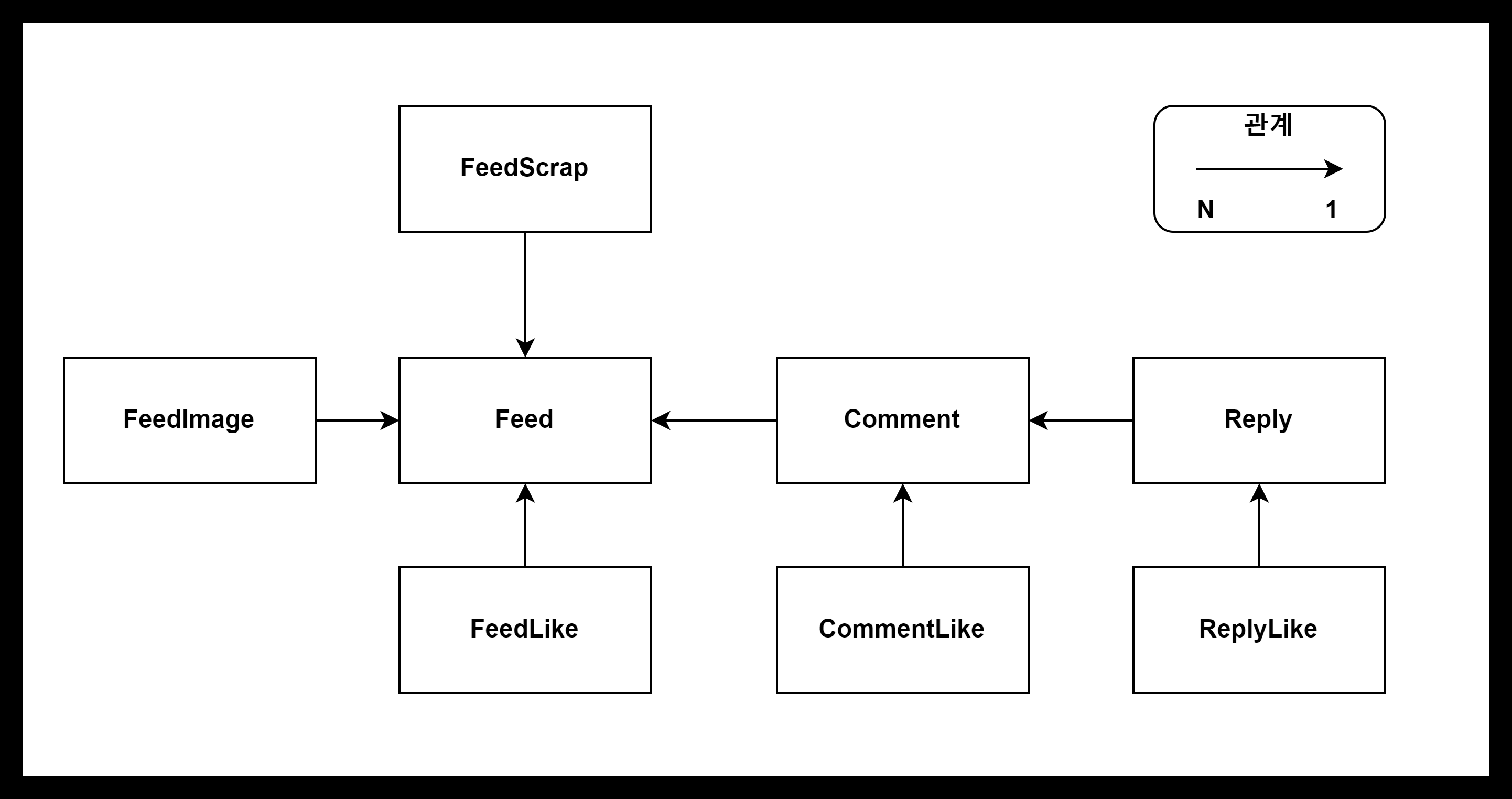
하지만 기능을 개발한 이후, JPA의 Delete 쿼리에서 발생한 로그를 확인하고, 뭔가 이상함을 느꼈습니다.
문제점
DataJpa의 delete(), deleteAll() 을 사용해서 피드를 삭제했는데, 쿼리가 상당히 이상하게 나가는 것을 확인했습니다. 뭔가 각 Entity마다 하나의 Delete 쿼리가 나갈 것이라고 상상했는데, Delete 쿼리가 굉장히 많이 나가는 것입니다. 아마 이 글을 읽고 있는 개발자분들도 delete 쿼리가 몇십 개씩 나가고 있다면 '이게 뭐지?' 하는 생각이 드실 거 같습니다..

아무튼... 이 상황에 대해서 좀 더 알아보기 위해서, 조사를 하던 중, 인프런 CTO인 향로님의 블로그에서 2017년에 남긴 글을 확인했습니다.
https://jojoldu.tistory.com/235
JPA에서 대량의 데이터를 삭제할때 주의해야할 점
안녕하세요? 이번 시간엔 JPA에서 대량의 데이터를 삭제할때 주의해야할 점을 샘플예제로 소개드리려고 합니다. 모든 코드는 Github에 있기 때문에 함께 보시면 더 이해하기 쉬우실 것 같습니다. (
jojoldu.tistory.com
향로님도 Delete 쿼리의 성능이 너무 나오지 않는 것을 확인하시고, 원인을 알아보던 과정에서 Delete Query가 N번 나오는 것을 파악했습니다. 그리고 JPQL을 활용해 in 쿼리를 사용해서 삭제하는 방법을 이용하면 쿼리가 나가는 횟수가 줄어들기 때문에, 더 효율적인 방법이 될 수 있다고 작성하셨습니다.
당연히 쿼리가 N번 나가는 것에서 1번 나가는 것으로 줄어들면, 더 빨라지겠지만, 저는 어느 정도나 빨라질지 궁금해져서, 예제 프로젝트를 만들어서 성능을 체크해 보기로 했습니다.
테스트
예제 프로젝트는 간단하게 Team과 Member 1:N 관계에서의 삭제를 테스트해보겠습니다.
Team과 Member의 클래스는 다음과 같이 구성되어 있습니다.
public class Team{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
@OneToMany(mappedBy = "team", cascade = CascadeType.REMOVE)
private List<Member> members;
(...)
}
public class Member{
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
private Integer age;
@JoinColumn(name = "team_id")
@ManyToOne(fetch = FetchType.LAZY)
private Team team;
(...)
}
Team과 Member를 각각 생성한 후, 삭제 테스트를 진행해 보겠습니다.
@BeforeEach
void beforeEach() {
for (int i = 0; i < 10; i++) {
Team team = new Team("팀" + i);
em.persist(team);
for (int j = 0; j < 1000; j++) {
Member member = new Member("회원" + j, 25);
member.associatedWithTeam(team);
em.persist(member);
}
}
em.flush();
em.clear();
}
case1. Delete with Cascade
첫 번째로는 기존에 적용하던 Cascade.Remove 옵션을 사용한 채로, 1 관계인 Team을 삭제하는 케이스입니다.
별다른 방법은 사용하지 않고, Spring Data JPA에서 제공하는 deleteAll() 메서드를 이용했습니다.
@Test
void deleteByCascade() throws Exception {
long start = System.currentTimeMillis();
teamRepository.deleteAll();
em.flush();
long end = System.currentTimeMillis();
logPerf(log, "delete by cascade", start, end); // [delete by cascade] cost 548ms
}
아래 결과 로그를 보면 548ms가 걸렸고... 앞서 작성했던 것처럼 `delete from member where id=?` 라는 구문이 굉장히 많이 찍혀있는 것을 확인할 수 있습니다.

향로님의 블로그의 글을 통해, 대략적으로 어떤 쿼리가 나오는지는 파악했지만, 모든 로그를 확인하면서 정리를 해봅시다.
기존에 Team을 10개, Member를 각 1000개씩 만들었다면 Team을 2개, Member를 3개만 넣고 쿼리를 다시 알아보겠습니다. 그 결과로 아래와 같은 로그가 나왔습니다.
Hibernate: select t1_0.id,t1_0.created_at,t1_0.name,t1_0.updated_at from team t1_0
Hibernate: select m1_0.team_id,m1_0.id,m1_0.age,m1_0.created_at,m1_0.name,m1_0.updated_at from member m1_0 where m1_0.team_id=?
Hibernate: select m1_0.team_id,m1_0.id,m1_0.age,m1_0.created_at,m1_0.name,m1_0.updated_at from member m1_0 where m1_0.team_id=?
Hibernate: delete from member where id=?
Hibernate: delete from member where id=?
Hibernate: delete from member where id=?
Hibernate: delete from team where id=?
Hibernate: delete from member where id=?
Hibernate: delete from member where id=?
Hibernate: delete from member where id=?
Hibernate: delete from team where id=?
위의 쿼리 내용을 정리하면 다음과 같습니다.
- Team에 대한 전체 조회
(1의 결과만큼 반복)
- Team ID에 해당하는 Member들 조회
- Member의 ID에 해당하는 회원 삭제 반복
- Team 삭제
그리고 쿼리가 나가는 횟수를 포함해서 정리하면 다음과 같이 볼 수 있습니다.
Team이 N개, 각 Team당 Member가 M개라고 할 경우
- Team에 대한 전체 조회 (1회)
- 각 Team에 해당하는 Member조회 쿼리 (N회)
- Member 삭제 쿼리 ( N * M 회)
- Team delete query ( N회 )
1 + (M+2) N 개의 쿼리가 나가게 되는 것입니다.
첫 케이스의 경우 Team이 10개, 각 팀당 Member가 1000개이니, 10,021개의 쿼리가 나가는 것입니다.
그럼 향로님의 블로그의 방법을 통해 삭제 쿼리를 줄인다면 어떻게 될까요?
case2. Delete with where in query
이 방법은 spring data jpa에서 제공하는 메서드를 사용하지 않고, jpql을 활용해 직접 쿼리를 작성합니다. 값을 삭제할 때, where in 쿼리를 활용하는 방법입니다. N 관계에 속한 Entity인 경우 in 쿼리에 fk를 넣는 것, 1인 경우는 pk를 넣는 것으로 쿼리를 줄어나갔습니다.
JPQL을 활용해 작성한 메서드는 다음과 같습니다.
public interface MemberRepository extends JpaRepository<Member, Integer> {
@Query("delete from Member m where m.team.id in :teamIds")
@Modifying
void deleteAllByTeam_IdIn(List<Integer> teamIds);
}
public interface TeamRepository extends JpaRepository<Team, Integer> {
@Query("select t.id from Team t")
List<Integer> findAllIds();
@Query("delete from Team t where t.id in :ids")
@Modifying
int deleteByIdIn(List<Integer> ids);
}
그럼 이 방법을 활용해서 동일한 환경에서 테스트를 진행해 보겠습니다.
@Test
void deleteQueryImprove() throws Exception {
long start = System.currentTimeMillis();
List<Integer> teamids = teamRepository.findAllIds();
memberRepository.deleteAllByTeam_IdIn(teamids);
teamRepository.deleteByIdIn(teamids);
em.flush();
long end = System.currentTimeMillis();
logPerf(log, "deleteQueryImprove", start, end); // [deleteQueryImprove] cost 127ms
/*
Hibernate: select t1_0.id from team t1_0
Hibernate: delete from member where team_id in (?,?,?,?,?,?,?,?,?,?)
Hibernate: delete from team where id in (?,?,?,?,?,?,?,?,?,?)
*/
}

앞선 delete()에 비해서 쿼리의 수가 굉장히 적어진 것을 확인할 수 있습니다. 1만 개가 넘는 쿼리에서 3개로 줄었으니, 시간 감소도 당연해 보입니다. 548ms -> 127ms로 대략 75%의 성능 개선을 이뤄낼 수 있었습니다. 정말 완벽한 방법이네요.
정리
지금까지 프로젝트에서 피드를 삭제하려는 API를 개발하면서, Spring Data JPA를 활용한 delete 쿼리 사용 시에 쿼리가 어떤 형태로 나가는지에 대해서 살펴봤고, 향로님 블로그에 나온 방법과 그 방법을 적용한 테스트를 살펴봤습니다.
정말 압도적인 성능 개선이 발생해서 상당히 놀라웠습니다. 방법에 대한 검증이 끝났으니 프로젝트에 적용해 보는 일만 남았겠죠?
미리 말하지만 사실 이 방법을 적용했지만 성능 개선은 실패했습니다. 자세한 내용은 다음 글을 통해서 살펴보겠습니다. 다음 글에서는 프로젝트에 적용한 결과와 어떤 이유로 실패했고, 최종적으로 어떤 방법을 선택했는지에 대해서 작성하겠습니다.

참고 자료
https://jojoldu.tistory.com/235
JPA에서 대량의 데이터를 삭제할때 주의해야할 점
안녕하세요? 이번 시간엔 JPA에서 대량의 데이터를 삭제할때 주의해야할 점을 샘플예제로 소개드리려고 합니다. 모든 코드는 Github에 있기 때문에 함께 보시면 더 이해하기 쉬우실 것 같습니다. (
jojoldu.tistory.com