'JPA의 N+1 문제'라는 이야기는 JPA를 사용하는 사람이라면 반드시 들어봤을 문제이다. N+1 문제로 인해서 성능 문제도 발생한다고 하기 때문에, JPA를 사용하는데 성능이 떨어진다면, N+1 문제가 발생하지 않은지 항상 확인해야 한다고들 말한다. 면접에서도 자주 묻는다는 N+1 문제가 도대체 무엇인지, 왜 발생하는지, 어떤 영향을 주고, 어떻게 해결하는지에 대해서 알아보자.
N+1 문제란?
N+1 문제는 하나의 엔티티를 조회할 때, 해당 엔티티와 연관된 엔티티에 접근할 때, 지연 로딩 전략에 따라서 추가적인 쿼리가 N번(처음 조회된 엔티티의 개수)만큼 나가는 것을 의미한다.
예시 코드를 보며 이해를 해보자.
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team", cascade = CascadeType.ALL)
private List<Member> members;
}
@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
private String name;
private Integer age;
@JoinColumn(name = "team_id")
@ManyToOne(fetch = FetchType.LAZY)
private Team team;
}
`Team`과 `Member` 는 1 : N의 관계를 갖는다. 여기서 `Team`을 조회한 후 members 변수를 조회하는 경우엔 지연 로딩 전략에 따라서 팀과 관련된 회원들에 대한 정보를 조회하는 쿼리가 발생할 것이다. 여기까지는 당연한 이야기다.
잠시 지연 로딩에 대해서 알아보자.
지연 로딩(Lazy Loading)이란?
지연 로딩 전략은 특정 엔티티를 조회할 때, 연관된 엔티티를 즉시 조회하지 않고, 필요할 때 조회하는 전략이다. 지연 로딩을 사용하지 않았는다면, 특정 엔티티와 연관된 모든 정보들이 조회될 것이다. 필요하지 않는 데이터를 조회하는 것은 불필요한 비용이 추가적으로 발생하기 때문에, 지연 로딩 전략을 이용한다.
다시 N+1 문제로 돌아와서, 지연 로딩이 설정된 엔티티 상황에서 연관 관계가 있는 엔티티에 접근하게 되면, 추가적인 쿼리가 발생할 것이다. 하지만 특정 API의 결과로 첫번째 조회 쿼리의 결과가 N번 발생한 상황에서, 연관된 엔티티에 접근을 한다면 어떻게 될까?
예시를 들어보자.
팀이 3개가 있고, 각자 회원이 2명씩 있다고 한다고 하자.
그럼 처음엔 팀을 조회하는 쿼리가 날아갈 것이다.
이후엔 3개의 팀에 대해서 각각 회원에 대한 쿼리가 날아갈 것이다.
즉, 1 (팀 전체 조회) + 3(팀의 개수) 번의 쿼리가 나가는 것이고, 첫번째 조회 쿼리의 결과 개수를 N이라고 보면 1+N개의 쿼리가 나가는 것이다.
아래 예시 코드를 확인하고 결과를 예상해보자. `ResponseDto`라는 클래스를 생성하는 과정에서 팀의 회원들에 접근하기 때문에, lazy loading이 발생할 것이고, 각각의 팀에 대해서, 팀에 속한 회원들을 조회하는 쿼리가 3번이 나갈 것이다.
public List<ResponseDto> getTeamData(){
return teamRepository.findAll().stream().map(ResponseDto::new)
.toList();
}
@Data
public class ResponseDto {
private String teamName;
private List<MemberResponse> memberResponse;
public ResponseDto(Team team) {
this.teamName = team.getName();
memberResponse = team.getMembers()
.stream()
.map(MemberResponse::new)
.toList();
}
@Data
private static class MemberResponse{
private String name;
private int age;
public MemberResponse(Member member) {
this.name = member.getName();
this.age = member.getAge();
}
}
}
역시 예상대로 1 + 3의 쿼리가 날아갔다.
Hibernate: select t1_0.id,t1_0.name from team t1_0
Hibernate: select m1_0.team_id,m1_0.id,m1_0.age,m1_0.name from member m1_0 where m1_0.team_id=?
Hibernate: select m1_0.team_id,m1_0.id,m1_0.age,m1_0.name from member m1_0 where m1_0.team_id=?
Hibernate: select m1_0.team_id,m1_0.id,m1_0.age,m1_0.name from member m1_0 where m1_0.team_id=?
어떤 문제가 발생하는가?
앞서 살펴본 것처럼 N+1 문제가 발생하면 처음의 조회 결과만큼의 추가 쿼리가 발생한다. 위의 케이스에서는 팀과 연관된 클래스가 회원밖에 없었기 때문에, N번밖에 발생하지 않았다. 하지만 연관된 엔티티가 많을수록 N * M 번의 쿼리가 발생할 수 있고, 쿼리가 많이 발생할수록 DB와의 통신이 발생하기 때문에 성능에 악영향을 줄 수밖에 없다.
N+1 문제를 해결하는 방법
N+1 문제를 해결하는 방법은 4가지가 있다. 각각의 방법에 대해서 알아보자.
1. FetchType.Eager
첫 번째 방법은 Lazy Loading을 사용하지 않고 즉시 조회 전략(FetchType.Eager)을 이용하는 것이다. 하지만 Lazy Loading을 통해 얻을 수 있는 장점이 사라지기 때문에, 추천되지 않는다.
2. @EntityGraph
두 번째 방법은 Entity Graph를 이용하는 방법이다. Entity Graph에 대해서는 잘 모르기 때문에, Java와 Spring과 관련된 여러 튜토리얼을 올리는 사이트인 Baeldung이 설명한 내용을 인용한다.
Until JPA 2.0, to load an entity association, we usually used FetchType.LAZY and FetchType.EAGER as fetching strategies. This instructs the JPA provider to additionally fetch the related association or not. Unfortunately, this meta configuration is static and doesn’t allow switching between these two strategies at runtime.
The main goal of the JPA Entity Graph is then to improve the runtime performance when loading the entity’s related associations and basic fields.
JPA 2.0까지는 엔티티 연결을 로드하기 위해 보통 FetchType.LAZy와 FetchType.EAGER를 페치 전략으로 사용했습니다. 이는 JPA 제공자에게 관련 연결을 추가로 페치할지 여부를 지시합니다. 불행히도 이 메타 구성은 정적이며 런타임 시 이 두 전략 간의 전환을 허용하지 않습니다.
JPA 엔티티 그래프의 주요 목표는 엔티티의 관련 연관성 및 기본 필드를 로드할 때 런타임 성능을 향상시키는 것입니다.
라고 설명한다. 주어진 예제를 살펴보면 Spring Data Jpa를 사용하는 상황이라면 클래스 레벨에 Entity Graph에 대한 점을 선언해 주고, 이후 조회를 할 때, 함께 사용한다.
위에서 살펴본 `Team` 클래스에 아래 어노테이션을 추가해준다.
@NamedEntityGraph(name = "Team.members",
attributeNodes = @NamedAttributeNode("members"))
그리고 Repository에는 @EntityGraph 어노테이션을 사용한다.
@EntityGraph("Team.members")
@Query("select t from Team t")
List<Team> selectAll();
@Override
@EntityGraph("Team.members")
List<Team> findAll();
다른 예제들을 살펴봤을 땐, 주로 findAll() 메서드를 재정의해서 사용하는데, 위의 selectAll 코드처럼 직접 작성한 코드에서도 추가적으로 Member와 join 하여 결과를 출력한다. (사실 findAll도 동일한 쿼리라서 당연했을지도 모르겠다)
Hibernate: select t1_0.id,m1_0.team_id,m1_0.id,m1_0.age,m1_0.name,t1_0.name from team t1_0 left join member m1_0 on t1_0.id=m1_0.team_id
3. @BatchSize
세 번째 방법은 @BatchSize를 사용하는 방법이다
BatchSize를 이용하면 EntityGraph처럼 join을 해서 결과를 가져오지는 않는다. 하지만 N+1 이 발생하는 첫 번째 조회 쿼리의 결과인 엔티티의 아이디를 in 절에 넣어서 연관된 엔티티를 조회할 때 사용한다고 한다. 하지만 스프링부트의 버전이 올라가면 다른 방법을 이용한다고 한다.
스프링부트 3.1 버전, 하이버네이트 6.2 버전부터는 성능 최적화를 위해 where in 절이 아닌 array_contains을 사용한다.
- 실전! 스프링 부트와 JPA 활용 2 - API 개발과 성능 최적화 김영한
@BatchSize를 설정한 후의 쿼리도 알아보자. BatchSize는 주로 100~1000 사이로 설정하는 것이 좋다고 한다. 그래서 일단 100으로 설정해 보았다.
@BatchSize(size = 100)
@OneToMany(mappedBy = "team", cascade = CascadeType.ALL)
private List<Member> members = new ArrayList<>();
예상한 대로, 첫 번째로 엔티티를 조회하는 쿼리가 나왔습니다. 하지만 위에서 말한 array_contains 쿼리가 아닌 where in 쿼리가 나온 것은 예상 밖이었는데요. 관련된 정보를 찾으려고 했는데, 글 작성 시점에는 알아내지 못해서 추후에 내용을 알아낸다면 추가하도록 하겠습니다.
Hibernate: select t1_0.id,t1_0.name from team t1_0
Hibernate: select m1_0.team_id,m1_0.id,m1_0.age,m1_0.name from member m1_0 where m1_0.team_id in (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)
4. Fetch Join
N+1을 해결하는 마지막 방법은 Fetch Join을 이용하는 것입니다.
Fetch Join은 JPQL을 작성할 때, join절이 끝난 후 fetch를 작성해 주면 됩니다.
@Query("select distinct t from Team t join fetch t.members")
List<Team> selectFetch();
Fetch Join을 사용하면 Entity Graph와 마찬가지로 필요에 따라서 Lazy Loading이 발생하지 않게 할 수 있고, Entity Graph에 비해서 적게 입력해도 되기 때문에, 주로 권장되는 방법입니다.
하지만 Fetch Join은 OneToMany관계가 여러 개가 있는 경우엔 사용할 수 없습니다. 하지만 ManyToOne인 경우엔 마음껏 사용할 수 있고, OneToMany관계에서는 @BatchSize와 함께 사용한다면, 문제를 해결할 수 있습니다.
그렇지만 페이징 상황에서는 이용할 수 없으니 주의해서 사용해야 합니다.
쿼리 결과는 아래와 같이 나옵니다.
Hibernate: select distinct t1_0.id,m1_0.team_id,m1_0.id,m1_0.age,m1_0.name,t1_0.name from team t1_0 join member m1_0 on t1_0.id=m1_0.team_id
각 방법 별 성능 비교
일반조회, FetchJoin, EntityGraph, BatchSize에 대해 JMeter를 이용하여 성능 테스트를 돌려봤습니다.
테스트 상황은 100개의 팀 클래스가 각각 3개의 멤버를 보유하고 있는 팀 클래스를 위에서 살펴본 `ResponseDto`로 변환하여 리턴했습니다.
가상 유저는 10000명이고 5초에 나눠서 접근하도록 설정했습니다.
그에 대한 결과입니다.
일반 조회

FetchJoin

@EntityGraph
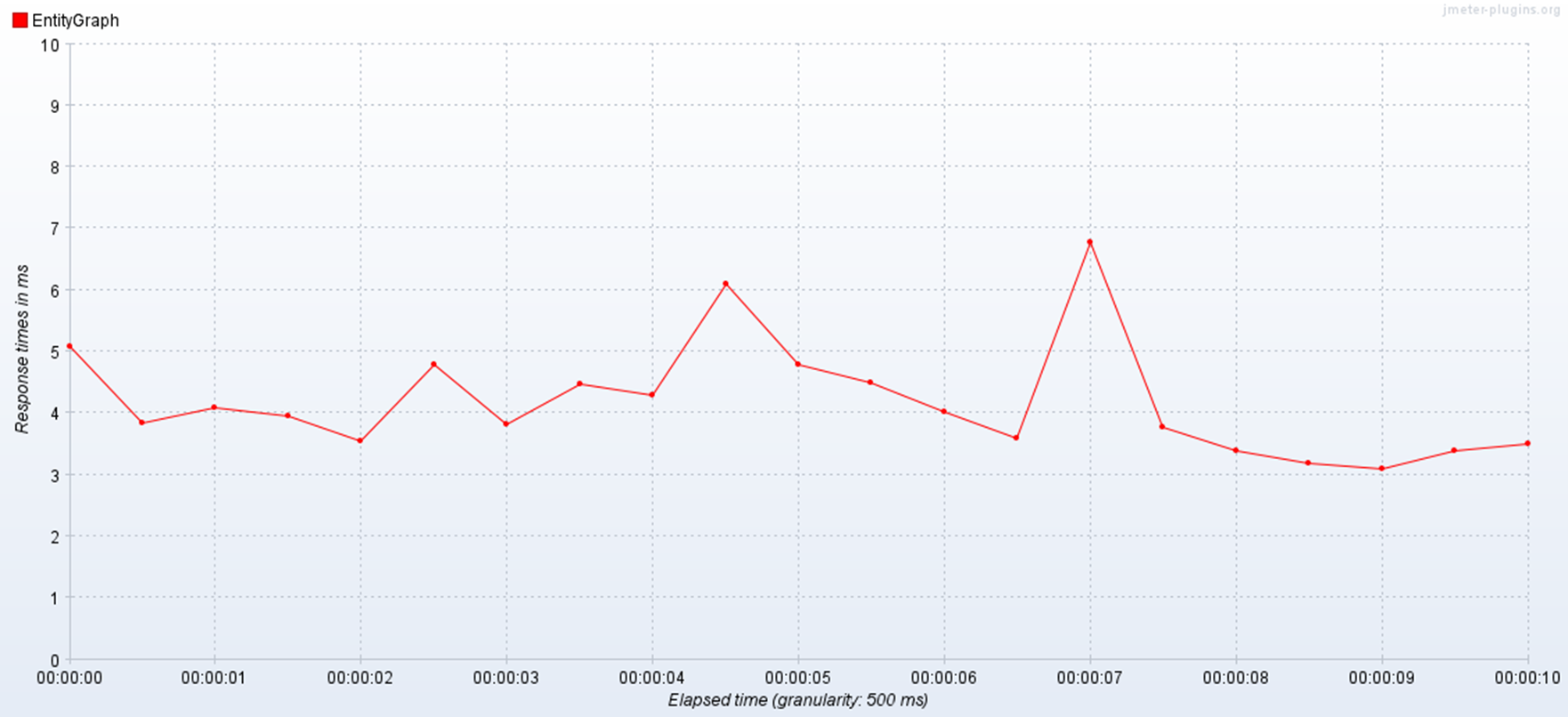
@BatchSize

@EntityGraph와 FetchJoin의 경우는 나가는 쿼리가 동일하기 때문에 거의 동일한 성능을 보이고, BatchSize 역시 큰 차이를 보이지는 않았습니다. 그에 반면 N+1이 발생하는 일반 조회의 경우는 어마어마하게 느린 것을 확인할 수 있었습니다.
지금까지 N+1 문제에 대해서 알아보았습니다. 마지막 성능 테스트까지 진행해 보니 왜 이 문제가 유명한지, 면접에서 많이 물어보는지에 대해서 알 수 있었습니다. 보통 최적화는 문제가 발생하면 진행하는 것을 추천하던데 N+1 문제와 같은 경우는 너무 유명하기도 하고, 성능에 악영향을 끼치는 것이 크니까 위에서 다룬 내용들을 잘 기억해 두고 바로 적용해 봐도 좋을 것 같습니다.
참고 자료
https://programmer93.tistory.com/83
https://www.baeldung.com/jpa-entity-graph
https://www.baeldung.com/spring-data-jpa-named-entity-graphs
김영한 - 실전! 스프링 부트와 JPA활용 2 - API 개발과 성능 최적화