질문 & 답변
Q. Java의 Hashtable 클래스와 HashMap 클래스의 공통점과 차이점에 대해서 설명해 주세요.
🙋🏻♂️ : `Hashtable` 클래스와 `HashMap` 클래스는 모두 `Hashtable` 자료구조를 구현한 클래스입니다. 둘의 차이점은 크게 `synchronized` 키워드의 유무와 `null` 허용유무가 있습니다.
`Hashtable` 클래스는 메서드에 `synchronized` 키워드가 붙어있고, `null`이 저장되는 것을 허용하지 않습니다. 그에 반면 `HashMap`클래스는 `synchronized` 키워드가 없고, `null`이 저장되는 것을 허용합니다.
자바의 docs에 따르면, 동시성 문제가 발생하지 않는다면 `HashMap`을 이용하고 Thread-Safe 해야 한다면, `Hashtable`보단 새로 생긴 `ConcurrentHashMap`을 이용하는 것을 권장합니다.
Q. `ConcurrentHashMap`을 권장하는 이유가 무엇인가요?
🙋🏻♂️ : `ConcurrentHashMap`은 `Hashtable` 클래스와 비슷하지만, Thread-Safe와 관련된 부분을 최소화하여 성능을 향상했습니다. `get()`메서드에선 `synchronized`키워드를 사용하지 않고, `put()` 메서드에선 메서드 전체에 `synchronized` 키워드를 사용한 `Hashtable`과 달리 필요한 부분에 동기화블록을 이용해서 동시성 문제와 관련된 부분을 최소화시켰습니다.
답변 근거
1. `Hashtable`은 synchronized 키워드가 있고, `HashMap`은 없다.
아래 두 사진을 보면 `Hashtable`의 `get()` 메서드엔 `synchronized` 키워드가 있고, `HashMap`의 `get()`과 `getNode()`에는 없다는 것을 확인할 수 있다. 물론 `put()`메서드에도 없다.
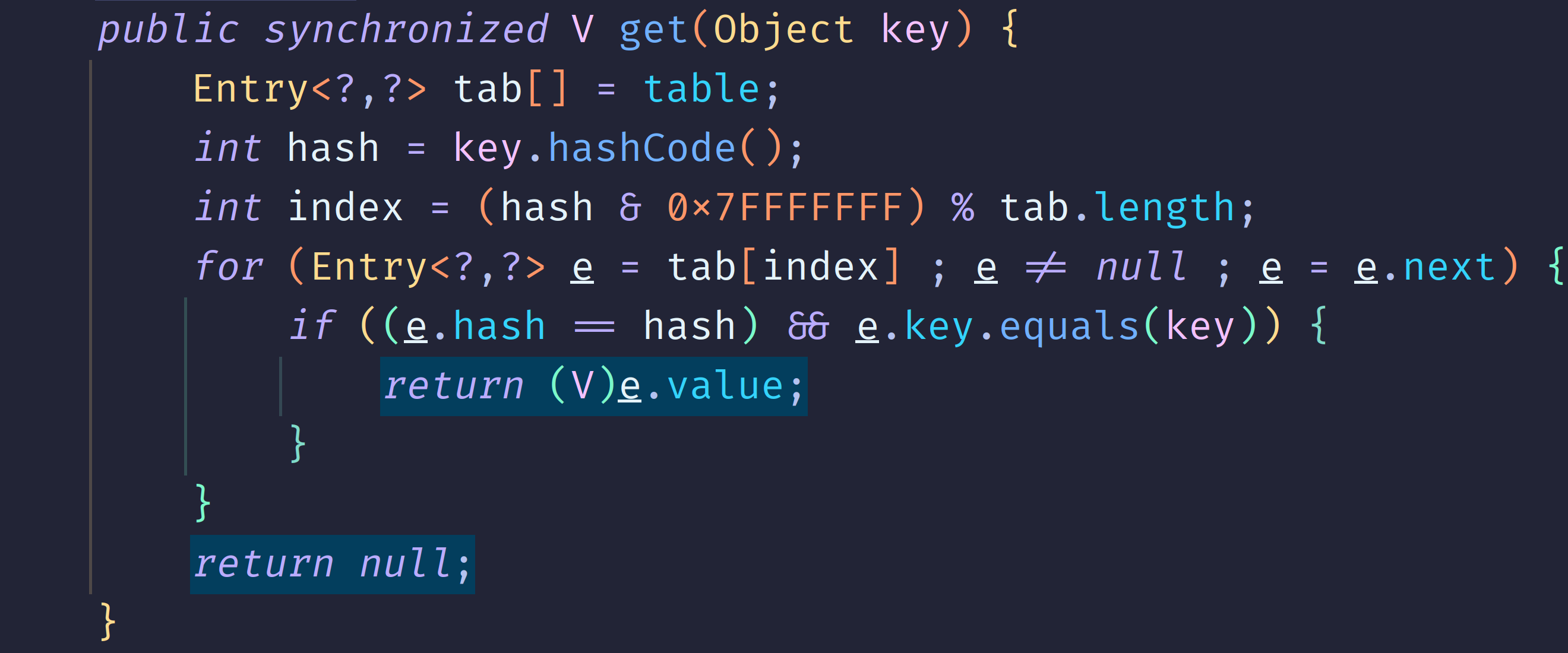
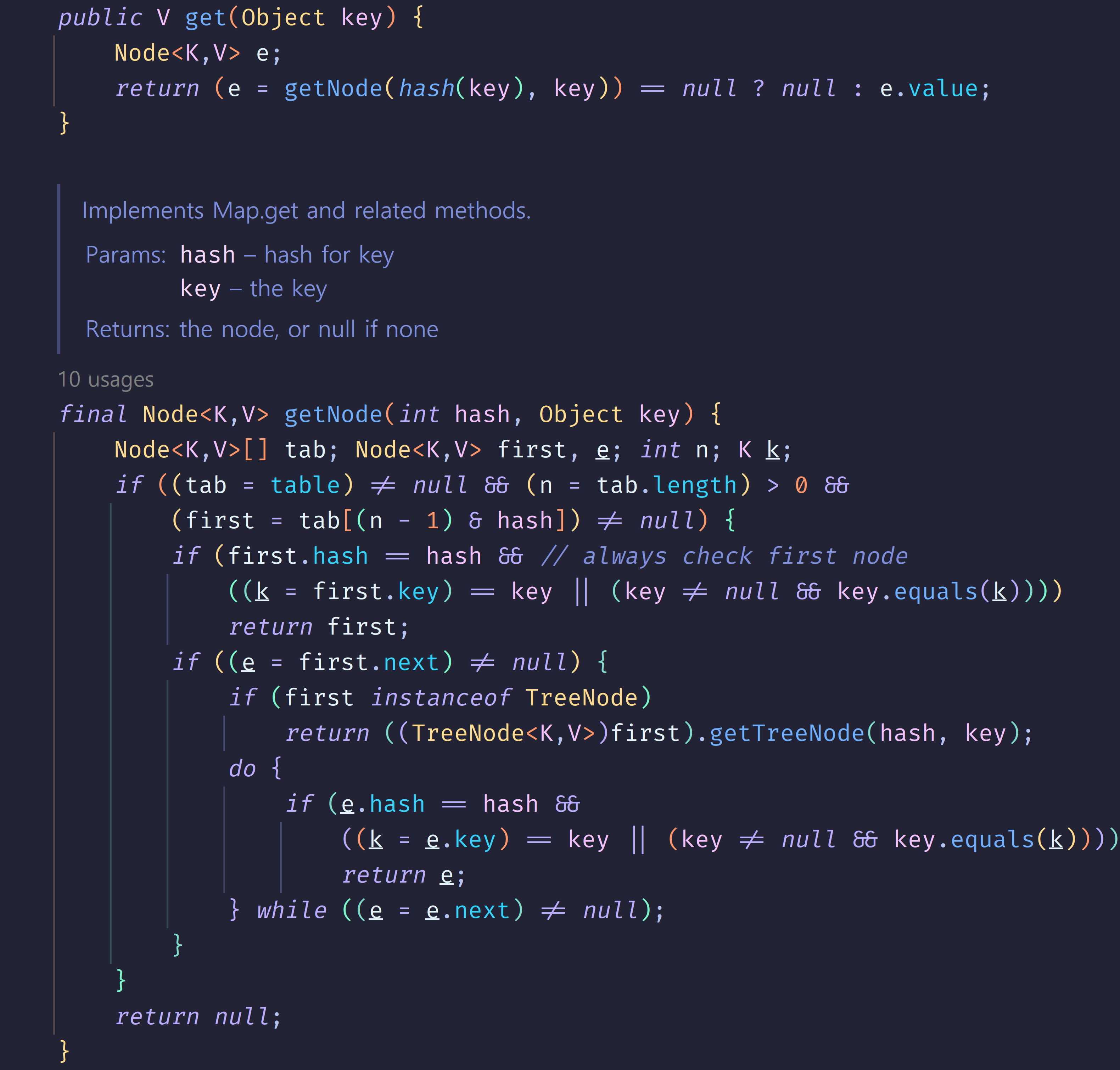
2. `Hashtable`은 null을 허용하지 않고, `HashMap`은 허용한다.
아래 코드는 `Hashtable`의 `put()`메서드이다. `key`와 `value`가 `null`이라면 NPE가 발생할 수 있다는 사실을 알 수 있다.
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
}
그와 달리 `HashMap`의 `put()`메서드를 살펴보자. `put()`에서 사용하는 `hash()` 메서드에서는 `key`가 `null`인 경우엔 해시값을 0을 리턴하도록 한다. `putVal()`메서드에서는 `value`에 대한 `null`체크가 따로 없으니 넘어간다.
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
아래 테스트코드와 같이 `HashMap`은 `key`와 `value`에 `null`을 넣어도 큰 문제없이 동작하지만, `Hashtable`의 경우, `NullPointerException`이 발생한 다는 것을 알 수 있다. 물론 테스트코드는 통과한다.
@Test
void 해시맵_해시테이블_테스트 () throws Exception{
Map<String, String> hashMap = new HashMap<>();
hashMap.put(null, "1234");
hashMap.put("1", null);
Map<String, String> hashtable = new Hashtable<>();
assertEquals(hashMap.get(null), "1234");
assertNull(hashMap.get("1"));
assertThrows(NullPointerException.class, () -> hashtable.put(null, "1234"));
assertThrows(NullPointerException.class, () -> hashtable.put("1", null));
}
3. `Hashtable`보다 `HashMap`을 사용하고, Thread-Safe이 필요한 상황이라면 `ConcurrentHashMap`을 이용하라.
해당 구절은 `Hashtable`의 docs에 적힌 내용을 인용했다.
As of the Java 2 platform v1.2, this class was retrofitted to implement the Map interface, making it a member of the Java Collections Framework. Unlike the new collection implementations, Hashtable is synchronized. If a thread-safe implementation is not needed, it is recommended to use HashMap in place of Hashtable. If a thread-safe highly concurrent implementation is desired, then it is recommended to use ConcurrentHashMap in place of Hashtable.
- Hashtable Java8 Docs
1번과 2번에서 `HashMap`이 Thread-Safe하지 않은 상황에서는 `Hashtable`보다 좋다는 것을 확인했다. `ConcurrentHashMap`을 더 권장하는 이유는 아래 4번에서 살펴보자.
4. `ConcurrentHashMap`을 권장하는 이유
이 부분 역시 `ConcurrentHashMap`의 Docs에 내용을 살펴보자.
A hash table supporting full concurrency of retrievals and high expected concurrency for updates. This class obeys the same functional specification as Hashtable, and includes versions of methods corresponding to each method of Hashtable. However, even though all operations are thread-safe, retrieval operations do not entail locking, and there is not any support for locking the entire table in a way that prevents all access. This class is fully interoperable with Hashtable in programs that rely on its thread safety but not on its synchronization details.
- ConcurrentHashMap Java8 Docs
이텔릭체로 표기한 부분을 보면 '모든 연산이 스레드 안전하지만, 검색 연산은 잠금을 수반하지 않으며, 모든 액세스를 방지하는 방식으로 전체 테이블을 잠그는 것은 지원되지 않습니다.'라는 뜻이다. 정확히 어떤 말인지 코드를 통해 살펴보자.
`Hashtable`의 경우 앞서 `get()`과 `put()`메서드에서 `synchronized`가 걸려있는 것을 확인했다. `ConcurrentHashMap`은 어떨까?
`get()`의 경우 위에서 말한 것처럼 `synchronized`가 존재하지 않는다.
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
그리고 `put()`의 경우, 메서드 전역에 `synchronized`가 설정된 `Hashtable`과 달리 내부에서 동기화블럭을 이용하여 동기화 처리의 영역을 최소화한 것을 알 수 있다.
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
...
synchronized (f) {
...
}
addCount(1L, binCount);
return null;
}
참고자료